






Web Scraping dla początkujących: wykorzystanie Pythona do gromadzenia danych

Dane stanowią fundament każdej decyzji biznesowej. Są niezbędne do prognozowania trendów, optymalizacji procesów, a także do lepszego zrozumienia zachowań klientów. Jednak gromadzenie tych danych może być trudne, zwłaszcza gdy mówimy o dużych ilościach informacji dostępnych online. Tutaj z pomocą przychodzi technika zwaną web scraping. Wykorzystując język programowania Python, możemy automatycznie gromadzić dane z różnych stron internetowych.
Czym jest web scraping?
Web scraping to technika ekstrakcji danych ze stron internetowych. W praktyce polega na napisaniu skryptu, który „przegląda” stronę internetową i zbiera z niej potrzebne informacje.
Web scraping jest niezwykle użyteczny, jeżeli chcemy zebrać duże ilości danych z internetu. Przykładowo, może być wykorzystany do zbierania informacji o cenach produktów z różnych sklepów internetowych, do tworzenia baz danych z ogłoszeń o pracę, czy do monitorowania opinii na temat firmy w mediach społecznościowych.
Jak zacząć z Pythonem?
Python to jeden z najpopularniejszych języków programowania, szczególnie ceniony za swoją czytelność i prostotę składni. Jest to język o ogromnej społeczności i mnóstwie dostępnych bibliotek, co czyni go idealnym narzędziem do web scrapingu.
Jeżeli jesteś początkujący, polecamy rozpocząć od naszego kursu programowania w języku Python od podstaw. Ten kurs zapewni Ci solidne podstawy, które pomogą Ci zrozumieć i wykorzystać Pythona do web scrapingu.
Narzędzia do web scrapingu w Pythonie
Python oferuje wiele bibliotek do web scrapingu, ale najbardziej popularne to BeautifulSoup i Scrapy.
- BeautifulSoup to biblioteka Pythona, która umożliwia parsowanie dokumentów HTML i XML. Jest łatwa w użyciu i idealna dla początkujących.
- Scrapy to bardziej zaawansowany framework do web scrapingu. Umożliwia tworzenie skomplikowanych skryptów do ekstrakcji danych, które mogą radzić sobie z różnymi problemami, takimi jak paginacja, sesje czy obsługa plików cookie.
Legalność i etyka web scrapingu
Web scraping jest techniką, która ma wiele zastosowań, ale pamiętaj, że nie wszystko, co technicznie możliwe, jest legalne lub etyczne. Zawsze upewnij się, że masz prawo do gromadzenia i wykorzystywania danych, które chcesz zgromadzić.
Pierwsze kroki w web scrapingu z Pythonem
Aby zacząć pracę z web scrapingiem w Pythonie, musimy najpierw zainstalować odpowiednie biblioteki. Możemy to zrobić za pomocą menedżera pakietów Pythona – pip:

Następnie, musimy zrozumieć strukturę strony, z której chcemy zgromadzić dane. Do tego celu przyda się narzędzie deweloperskie dostępne w większości przeglądarek internetowych (nazywane „Inspect” lub „Inspect Element”).
Gdy już znamy strukturę strony, możemy napisać skrypt, który będzie „przechodził” przez stronę i zbierał potrzebne nam dane. Oto bardzo prosty przykład skryptu, który korzysta z BeautifulSoup do wydobycia tytułów z głównej strony bloga:
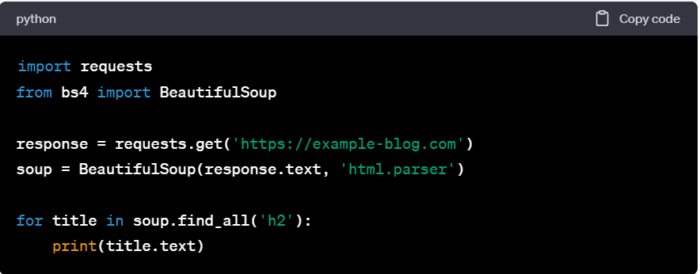
Dalsze kroki
Web scraping to potężne narzędzie, ale wymaga praktyki i czasu, aby opanować jego różne aspekty. Na Sciente oferujemy różne kursy z zakresu IT, które pomogą Ci zrozumieć i opanować web scraping oraz inne techniki związane z Pythonem.
Jeżeli jesteś zainteresowany innymi obszarami, takimi jak gotowanie, umiejętności miękkie, grafika czy kryptowaluty, mamy również coś dla Ciebie.
Na koniec, pamiętaj, że web scraping to tylko jedno z narzędzi w arsenale data scientist. Istnieje wiele innych technik i narzędzi, które można wykorzystać do zbierania, analizowania i interpretowania danych. Zapraszamy do zapoznania się z naszą ofertą kursów online, aby dowiedzieć się więcej.
Proponowany kurs

Dlaczego wybrać nasz kurs programowania Python?
Interesujesz się programowaniem i chciałbyś się nauczyć, jak to robić? Może jesteś początkującym programistą, który chce uzupełnić i zwiększyć swoją wiedzę? Mamy dla Ciebie kurs online, który Ci w tym pomoże!
Kurs Programowania Python: Idealny dla początkujących
Przygotowaliśmy kurs Python od podstaw, który nauczy Cię programować z wykorzystaniem języka Python. Jest to język programowania ogólnego przeznaczenia, który ma prostą składnię, co ułatwia czytanie i pisanie kodu. Pythona można wykorzystywać w wielu dziedzinach, takich jak tworzenie stron internetowych, nauka o danych, sztuczna inteligencja i wiele innych. Głównym założeniem Pythona jest zapewnienie prostoty i przejrzystości tak, aby nawet osoby początkujące mogły się go nauczyć w szybki i łatwy sposób. Python może być używany do prostych lub złożonych projektów, a także do tworzenia skryptów i automatyzacji.
Python jest językiem programowania o wielu zastosowaniach. Możesz go wykorzystać do tworzenia serwisów internetowych, aplikacji desktopowych działających na komputerach użytkowników, wliczając w to także gry. Python sprawdzi się także w aplikacjach sieciowych, czy skryptach np. generujących zestawienia i raporty.
Python kurs online pomoże Ci nauczyć się podstaw języka Python, a nawet dowiesz się jak utworzyć własną aplikację z graficznym interfejsem użytkownika. W kursie poznasz struktury języka i instrukcje, które umożliwią Ci rozpoczęcie przygody z programowaniem w sposób łatwy, szybki i przede wszystkim przyjemny. Nie musisz martwić się, że nie znasz innych języków i zasad programowania, nasz kurs pomoże Ci zacząć programować od zera. Jest to język idealny dla początkujących, a mimo to daje mnóstwo możliwości.
Szkolenie Python od podstaw: Klucz do sukcesu
Ponadto nasz kurs Python podstawy oferuje informacje, które pomogą Ci zrozumieć fundamentalne elementy języka. Będziesz mógł budować własne projekty, używając solidnej podstawy, jaką dostarczy Ci to szkolenie online.
Zrozumienie Python od podstaw jest kluczowe dla każdego, kto chce zostać programistą. Nasz kurs skupia się na dostarczeniu Ci tych podstawowych informacji, które pomogą Ci rozpocząć swoją karierę jako programista.
Jeżeli szukasz kursu z programowania, to nasza oferta jest dla Ciebie. Nasz kurs programowania Python został stworzony z myślą o tych, którzy chcą nauczyć się tego języka programowania, niezależnie od ich doświadczenia.
Jesli szukasz kursu programowania Python, nasze szkolenie online jest idealne. Nauczysz się wszystkiego, co musisz wiedzieć o tym języku programowania, od podstaw do bardziej zaawansowanych zagadnień.
Zaletą naszego kursu jest to, że jest to szkolenie online, co oznacza, że możesz uczyć się w swoim własnym tempie, z dowolnego miejsca, o dowolnej porze. Dostęp do kursu jest 24/7, więc możesz się uczyć wtedy, gdy to jest dla Ciebie najbardziej dogodne.
Przystąp do naszego kursu z Pythona!
Kurs programowania Python, który dla Ciebie przygotowaliśmy, nie wymaga od Ciebie znajomości programowania, wystarczą chęci i zaangażowanie. Nie czekaj, sprawdź nasz kurs online i naucz się programować, nie wychodząc z domu!
-
10









